Stats
Actions
Available In
Tags
By us
Self-host a complete web scraping and data extraction pipeline with a Firecrawl-compatible API. Map, crawl, scrape, and search websites using a single Rust binary; extract structured JSON, parse PDFs, detect page changes, and integrate with SearXNG for web search. Drop-in replacement for Firecrawl SDKs.
Scrape a single known URL into clean markdown / HTML / links / structured JSON with fastCRW. Use when you already have the URL and want the page content — "scrape", "grab", "fetch", "pull", "read this page", "get the content of". Handles JavaScript-rendered SPAs automatically. Step 2 of the crw workflow ladder.
Search the web with fastCRW and get titles, URLs, and descriptions. Use when you have a question or topic but not a URL — "search for", "find pages about", "look up", "what is", "who is", "latest news on", "find docs for". SearXNG-backed: self-hosted, no API key, no per-query cost, high recall via meta-search aggregation. Step 1 of the crw workflow ladder.
Stand up your own fastCRW API server — single binary, Docker, or docker-compose with a bundled SearXNG sidecar. Use when the user wants to run crw locally or on their own infra, configure renderers/proxies/ auth/LLM extraction, or understand the embedded vs proxy MCP modes.
Detect what changed between two page snapshots with fastCRW — stateless diff as a REST primitive. Use when you need to track content changes, monitor a page for updates, or build a cron-based alert system: "has this page changed?", "alert me when pricing changes", "diff this week's scrape against last week's". Step 7 of the crw workflow ladder.
Find ALL the arXiv papers that answer a research question, using fastCRW's Firecrawl-compatible Research API. Use when the ask is to survey a literature, enumerate papers on a topic, find what a paper compares against or builds on, list the best models on a benchmark, or recover a paper from a vague description — "papers that do X", "what does X benchmark against", "best open model on Y", "find the paper that ...". Reaches 61.0% recall on the ArXivQA benchmark vs Firecrawl's Research Index 53.3%.
Own this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimOwn this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimBased on adoption, maintenance, documentation, and repository signals. Not a security audit or endorsement.
![]()
Self-hosted, Rust-native web crawler & scraper for AI agents
The open-source alternative to Firecrawl. One static binary, ~50 MB RAM idle,
Firecrawl-compatible REST API on both /v1/* and /v2/* (scrape, crawl,
map, search, extract, plus v2 batch & parse) — a drop-in for the official
Firecrawl SDKs — plus first-class MCP. Self-host free under
AGPL-3.0, or hit our managed API at api.fastcrw.com. Reproducible 63.74%
truth-recall on the public 1,000-URL dataset (diagnose_3way.py,
2026-05-08) — see fastcrw.com/benchmarks.
Built in Rust because every millisecond of agent latency compounds.

![]()
![]()





Works with: Claude Code · Cursor · Windsurf · Cline · Copilot · Continue.dev · Codex · Gemini CLI
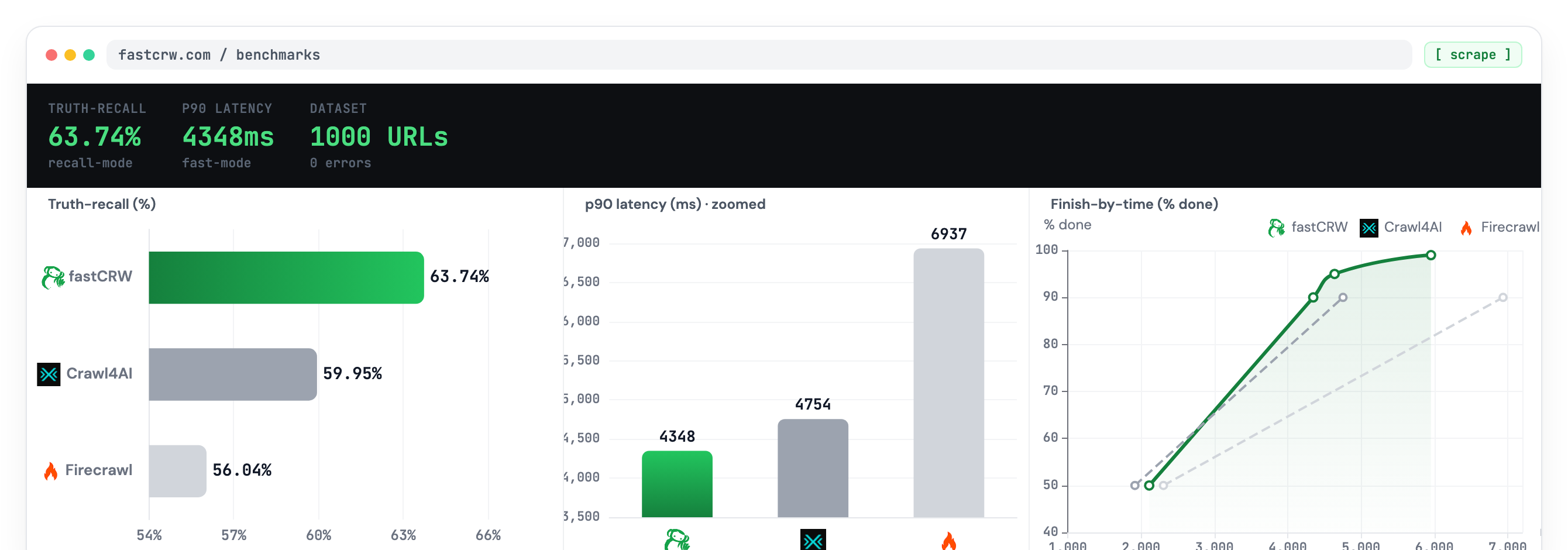
Firecrawl's own 1,000-URL public dataset (diagnose_3way.py) — fastCRW leads on truth-recall, median latency, and fast-mode p90. Full numbers and one-command repro ↓
npx claudepluginhub us/crw --plugin crwFind, recover, and resume your past Claude Code sessions from local history — keyword search, pre-compaction recovery, and worktree topology.
Scrape, search, crawl, and map the web with a single command.
Claude Code skill pack for FireCrawl (30 skills)
Firecrawl v2.5 API for web scraping/crawling to LLM-ready markdown. Use for site extraction, dynamic content, or encountering JavaScript rendering, bot detection, content loading errors.
The best web scraping tool for LLMs. USE --smart-extract to give your AI agent only the data it needs from any web page — extracts from JSON/HTML/XML/CSV/Markdown using path language with recursive search, filters, and regex. Handles JS, CAPTCHAs, anti-bot automatically. AI extraction in plain English. Google/Amazon/Walmart/YouTube/ChatGPT APIs. Batch, crawl, cron scheduling.
Official Apify agent skills for web scraping, data extraction, and automation
Web search, content extraction, and media download
'%20stop-opacity%3D'0.16'%2F%3E%3Cstop%20offset%3D'1'%20stop-color%3D'rgb(200%2C90%2C60)'%20stop-opacity%3D'0.03'%2F%3E%3C%2FlinearGradient%3E%3C%2Fdefs%3E%3Crect%20width%3D'320'%20height%3D'200'%20fill%3D'url(%23g)'%2F%3E%3Ccircle%20cx%3D'250'%20cy%3D'56'%20r%3D'92'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.06'%2F%3E%3Ccircle%20cx%3D'64'%20cy%3D'172'%20r%3D'58'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.05'%2F%3E%3C%2Fsvg%3E)